使用selenium的方式获取网页中图片的链接和网页的链接,来判断是否是死链(二)
上一篇使用Java正则表达式来判断和获取图片的链接以及跳转的网址,这篇使用selenium的自带的API(getAttribute)来获取网页中指定的内容
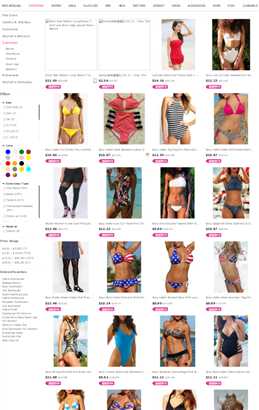
实现内容:获取下面所有图片的链接地址以及跳转地址,使用get请求判断是否有死链
页面内容如图:
页面的源码,需要获取页面的href后的地址,以及src后的地址,:
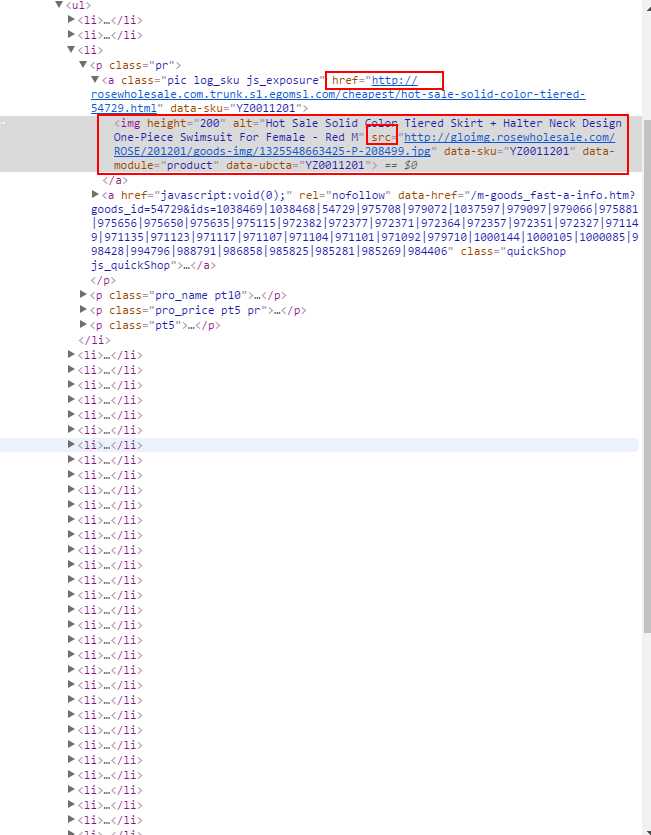
代码实现可以看出图片都在一个div中,实现的思想为:获取控件集合,在获取每一个li下的元素,在获取,在取出数据下的属性名的属性值
public void new_classification() throws Exception { op.loopGet(home, 40, 3, 60); op.loopClickElement("swimmer", 3, 10, explicitWaitTimeoutLoop);// 进入到某个页面 if (driver.getCurrentUrl().contains("swimwear")) { List<WebElement> newimage = driver.findElements(By.xpath("//*[@id=‘js_proList‘]/ul/li"));// 图片的控件集合 for (int i = 0; i < newimage.size(); i++) { String contentURL = newimage.get(i).findElement(By.xpath("p[1]/a[1]")).getAttribute("href");// 图片的跳转地址 String imageURL = newimage.get(i).findElement(By.xpath("p[1]/a[1]/img")).getAttribute("src");// 图片的链接地址 Pub.get(contentURL); System.out.println("**********************"); Pub.get(imageURL);//get请求 } } else { Log.logError("没有进入到new页面"); } }
结果展示

如果需要使用正则表达式,查看文章:http://www.cnblogs.com/chongyou/p/7286447.html
文章来自:http://www.cnblogs.com/chongyou/p/7286523.html