降噪自动编码器(Denoising Autoencoder)
起源:PCA、特征提取....
随着一些奇怪的高维数据出现,比如图像、语音,传统的统计学-机器学习方法遇到了前所未有的挑战。
数据维度过高,数据单调,噪声分布广,传统方法的“数值游戏”很难奏效。数据挖掘?已然挖不出有用的东西。
为了解决高维度的问题,出现的线性学习的PCA降维方法,PCA的数学理论确实无懈可击,但是却只对线性数据效果比较好。
于是,寻求简单的、自动的、智能的特征提取方法成了深度学习的研究重点。比如LeCun在1998年CNN总结性论文中就概括了今后机器学习模型的基本架构。
当然CNN另辟蹊径,利用卷积、降采样两大手段从信号数据的特点上很好的提取出了特征。对于一般非信号数据,该怎么办呢??
Part I 自动编码器(AutoEncoder)
自动编码器基于这样一个事实:原始input(设为x)经过加权(W、b)、映射(Sigmoid)之后得到y,再对y反向加权映射回来成为z。
通过反复迭代训练两组(W、b),使得误差函数最小,即尽可能保证z近似于x,即完美重构了x。
那么可以说正向第一组权(W、b)是成功的,很好的学习了input中的关键特征,不然也不会重构得如此完美。结构图如下:
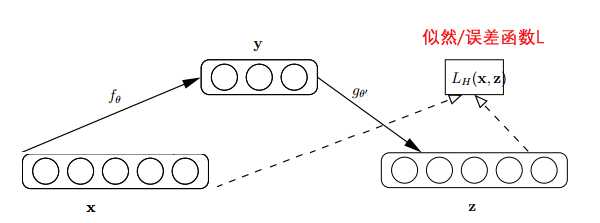
从生物的大脑角度考虑,可以这么理解,学习和重构就好像编码和解码一样。

这个过程很有趣,首先,它没有使用数据标签来计算误差update参数,所以是无监督学习。
其次,利用类似神经网络的双隐层的方式,简单粗暴地提取了样本的特征。
这个双隐层是有争议的,最初的编码器确实使用了两组(W,b),但是Vincent在2010的论文中做了研究,发现只要单组W就可以了。
即W‘=WT, W和W’称为Tied Weights。实验证明,W‘真的只是在打酱油,完全没有必要去做训练。
逆向重构矩阵让人想起了逆矩阵,若W-1=WT的话,W就是个正交矩阵了,即W是可以训成近似正交阵的。
由于W‘就是个酱油,训练完之后就没它事了。正向传播用W即可,相当于为input预先编个码,再导入到下一layer去。所以叫自动编码器,而不叫自动编码解码器。