caffe imagenet模型理解
example下imagenet文件夹下的train_caffenet.sh里面的配置文件为models/bvlc_reference_caffenet/solver.prototxt,找到了solver.prototxt,里面对应的模型为,models/bvlc_reference_caffenet/train_val.prototxt,所以本博文,主要描述的是models/bvlc_reference_caffenet/train_val.prototxt。而且从model文件夹里面可以看到有alenet。说明这个其实这里面调用的模型,跟论文ImageNet Classification with Deep Convolutional Neural Networks里的模型是有点区别了。不过差距不大,帮助理解论文里面模型的整体思路,还是很有帮助的。
本文主要参考:ImageNet Classification with deep convolutional neural networks
下面主要就是对模型bvlc_reference_caffenet/train_val.prototxt的理解,最开始也说明了,这是CaffeNet,说明这就是caffe调用的net了。
问题:
1、哎,这模型,由于渣显卡。我还没跑过。要跑起来,没跑过,写这博文,总感觉没底气。关于batchsize这块,都是看的[caffe]深度学习之图像分类模型AlexNet解读,上面最后输出的数据,所以以后自己能跑代码的时候,再回来看看有啥问题。
2、这数据里面又出现了mean_file: "data/ilsvrc12/imagenet_mean.binaryproto",这均值为啥了。
训练阶段:
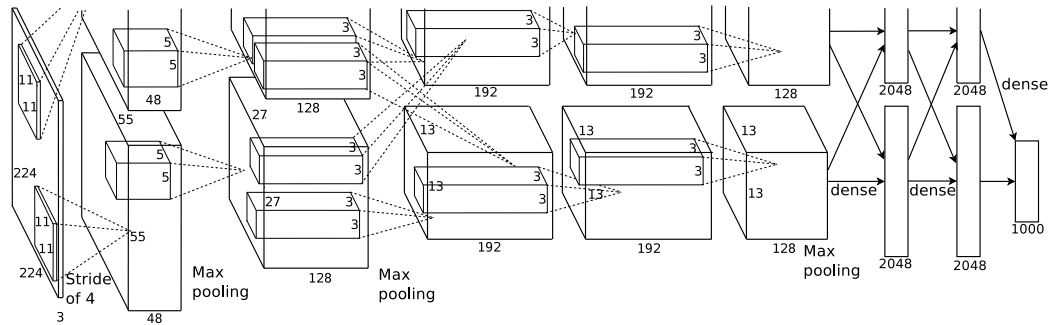
由于这个模型,前面几层把卷积和池化都合并了,所以如果当看图来说,相对于之前的MNIST,把卷积和池化层分开来画。这图没那么清晰的思路。
输入数据:数据为256 3 227 227。由于设置的batch_size: 256,而且输入的为227x227的RGB图像。所以输入的为256 3 227 227。其实这227x227,就跟那alexnet的数据224x224不同了。
第一层 第一个卷积层:数据变为256 96 55 55。跟论文中一样,也是96个核(不过这个据贾扬清自己说,这个是单GPU的模型了,不是双GPU)。每个核大小还是11x11,步长为4。看到一种更好的计算卷积后尺寸大小的方式:(227-11)/4+1=55。等于相当于减去了卷积核大小,然后看看有多少个步长,由于前面算的是中间的长度,然后+1,就是最后卷积后的特征的尺寸。这里其实也能看出为啥输入数据的尺寸变为227,就是为了对于卷积后得到55x55尺寸的特征图的情况下面,不会出现像论文中一样需要填充。这在我论文笔记里面也提到了要填3个像素。这等于把3个像素补上了,224+3=227。
ReLU,在卷积之后马上ReLU,这在cifar10模型中其实就有了,但是cifar10第二个卷积之后才ReLU的,这直接就ReLU了,不知道是出于哪方面考虑的,是数据量太大。需要马上稀疏来提取局部特征
第一层 第一个卷积层:数据变为