Exploiting second-order SQL injection 利用二阶注入获取数据库版本信息 SQL Injection Attacks and Defense Second Edition
w
SQL Injection Attacks and Defense Second Edition
Exploiting second-order SQL injection
Virtually every instance of SQL injection discussed in this book so far may be classified as
“first-order” SQL injection. This is because the events involved all occur within a single HTTP
request and response, as follows:
1 The attacker submits some crafted input in an HTTP request.
2 The application processes the input, causing the attacker’s injected SQL query to execute.
3 If applicable, the results of the query are returned to the attacker in the application’s response
to the request.
A different type of SQL injection attack is “second-order” SQL injection. Here, the
sequence of events is typically as follows:
1 The attacker submits some crafted input in an HTTP request.
2 The application stores that input for future use (usually in the database), and responds to the
request.
3 The attacker submits a second (different) request.
4 To handle the second request, the application retrieves the stored input and processes it,
causing the attacker’s injected SQL query to execute.
5 If applicable, the results of the query are returned to the attacker in the application’s response
to the second request.
Second-order SQL injection is just as powerful as the first-order equivalent; however, it is a
subtler vulnerability which is generally more difficult to detect.
Second-order SQL injection usually arises because of an easy mistake that developers make
when thinking about tainted and validated data. At the point where input is received directly
from users, it is clear that this input is potentially tainted, and so clued-in developers will make
some efforts to defend against first-order SQL injection, such as doubling up single quotes or
(preferably) using parameterized queries. However, if this input is persisted and later reused, it
may be less obvious that the data are still tainted, and some developers make the mistake of
handling the data unsafely at this point.
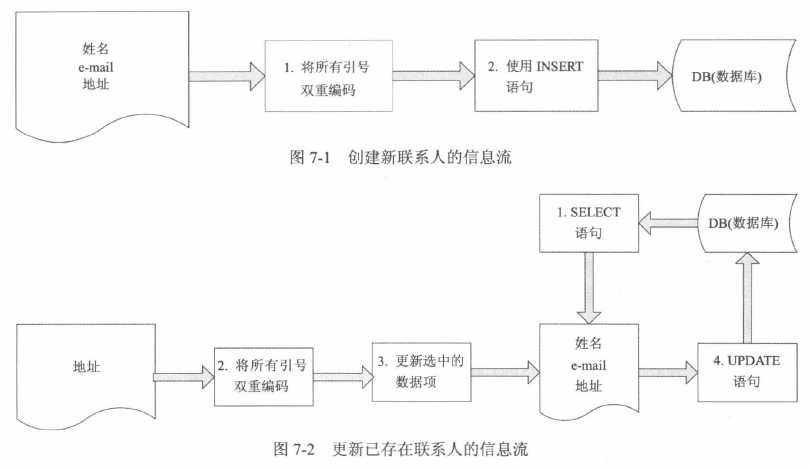
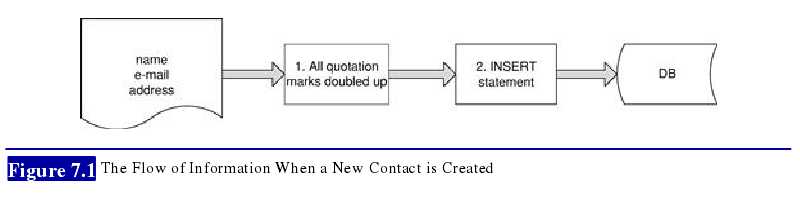
Consider an address book application which allows users to store contact information about
their friends. When creating a contact, the user can enter details such as name, e-mail, and
address. The application uses an INSERT statement to create a new database entry for the
contact, and doubles up any quotation marks in the input to prevent SQL injection attacks (see
Figure 7.1).
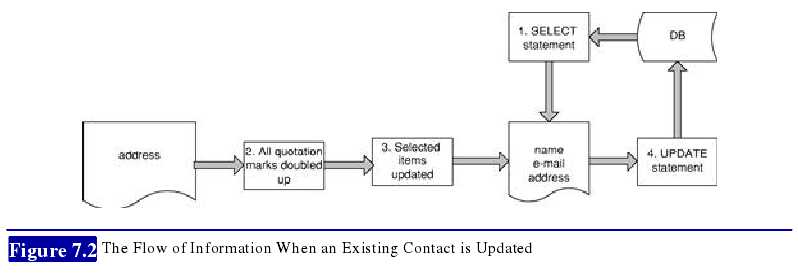
The application also allows users to modify selected details about an existing contact. When
a user modifies an existing contact, the application first uses a SELECT statement to retrieve
the current details about the contact, and holds the details in memory. It then updates the
relevant items with the new details provided by the user, again doubling up any quotation
marks in this input. Items which the user has not updated are left unchanged in memory. The
application then uses an UPDATE statement to write all of the in-memory items back to the
database (see Figure 7.2).
The quotes are doubled up in your input, and the resultant INSERT statement looks like this:
INSERT INTO tbl Contacts VALUES (‘a‘‘+@@version+’’a’, ‘foo@example.org’,…
Hence, the contact name is safely stored in the database, with the literal value that you
submitted.
Then, you need to go to the function to update the new contact, and provide a new value in
the address field only (any accepted value will do). When you do this, the application will first
retrieve the existing contact details, using the following statement:
SELECT
?
FROM tbl Users WHERE contact Id = 123
The retrieved details are stored briefly in memory. The value retrieved for the name field
will, of course, be the literal value that you originally submitted, because this is what was
stored in the database. The application replaces the retrieved address in memory with the new
value you supplied, taking care to double up quotation marks. It then performs the following
UPDATE statement to store the new information in the database:
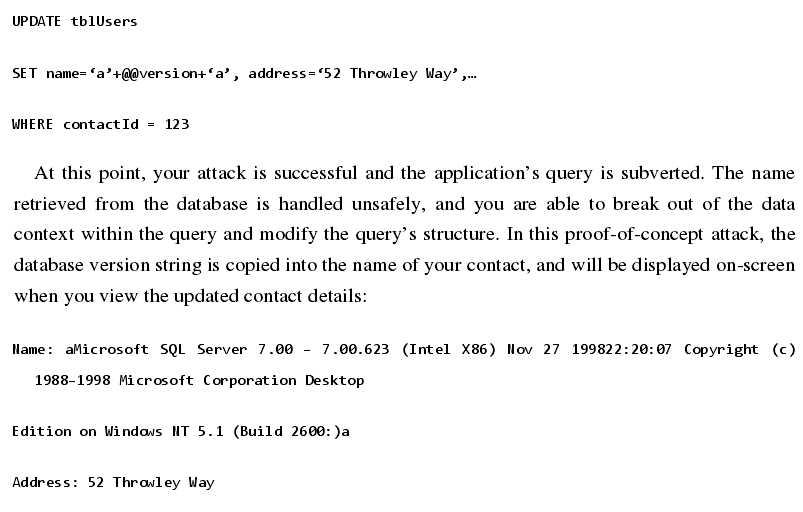
UPDATE tbl Users
SET name=‘a’+@@version+‘a’, address=‘52 Throwley Way’,…
WHERE contact Id = 123
At this point, your attack is successful and the application’s query is subverted. The name
retrieved from the database is handled unsafely, and you are able to break out of the data
context within the query and modify the query’s structure. In this proof-of-concept attack, the
database version string is copied into the name of your contact, and will be displayed on-screen
when you view the updated contact details:
Name: a Microsoft SQL Server 7.00 – 7.00.623 (Intel X86) Nov 27 199822:20:07 Copyright (c)
1988–1998 Microsoft Corporation Desktop
Edition on Windows NT 5.1 (Build 2600:)a
Address: 52 Throwley Way Let’s assume that the doubling up of quotation marks in this instance is effective in
preventing first-order SQL injection. Nevertheless, the application is still vulnerable to second-
order attacks. To exploit the vulnerability, you first need to create a contact with your attack
payload in one of the fields. Assuming the database is Microsoft SQL Server, create a contact
with the following name:
a‘+@@version+’a To perform a more effective attack, you would need to use the general techniques already
described for injecting into UPDATE statements (see Chapter 4), again placing your attacks
into one contact field and then updating a different field to trigger the vulnerability.