HTML基本格式(树型格式):
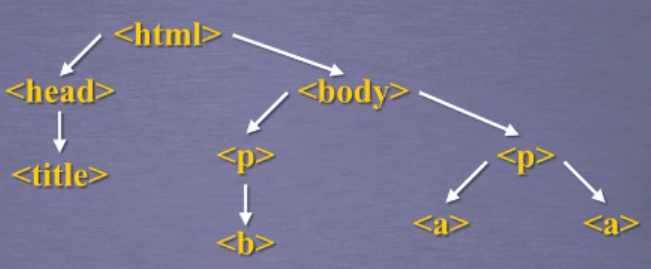
遍历方式:下行遍历(根节点到叶节点),上行遍历(叶节点到根节点),平行遍历
标签树的下行遍历:
| 属性 | 说明 |
| .contents | 子节点的列表,将<tag>所有儿子节点存入列表 |
| .children | 子节点的迭代类型,与.contents类似,用于循环遍历儿子节点 |
| .descendants | 子孙节点的迭代类型。包含所有子孙节点,用于循环遍历 |
下行遍历举例;
soup.head#获取head节点,返回<head><title>This is a python demo page</title></head> soup.head.contents#获取儿子节点,返回[<title>This is a python demo page</title>] soup.body.contents#body标签的contents信息 len(soup.body.contents)#儿子节点的个数,发现有5个,返回5 soup.body.contents[1]#利用列表操作获得特定儿子节点的信息 #返回<p class="title"><b>The demo python introduces several python courses.</b></p> #另两种遍历方法 ‘‘‘ 利用循环遍历儿子节点或子孙节点 for child in soup.body.children: print(child) 或者 for child in soup.body.descendants: print(child) ‘‘‘
标签树的上行遍历:
两个属性:
.parent 节点的父亲标签
.parents 节点先辈标签的迭代类型,用于循环遍历先辈节点
#上行遍历 soup.title.parent#title的父亲是head #返回 <head><title>This is a python demo page</title></head> soup.html.parent#html的父亲是自己
#标签树上行遍历代码汇总 soup=BeautifulSoup(demo,‘html.parser‘) for parent in soup.a.parents: if parent is None:#如果先辈是None print(parent) else: print(parent.name) #返回 ‘‘‘ p body html [document] ‘‘‘
标签树的平行遍历
| 属性 | 说明 |
| .next_sibling | 返回按照HTML文本顺序的下一个平行节点标签 |
| .previous_sibling | 返回按照HTML文本顺序的上一个平行节点标签 |
| .next_siblings | 迭代类型,返回按照HTML文本顺序的后续所有平行节点标签 |
| .previous_siblings | 迭代类型,返回按照HTML文本顺序的前续所有平行节点标签 |
所有的平行遍历必须发生在同一个父亲节点下

soup.a.next_sibling#返回‘ and ‘ soup.a.next_sibling.next_sibling #返回 <a class="py2" href="http://www.icourse163.org/course/BIT-1001870001" id="link2">Advanced Python</a> soup.a.previous_sibling soup.a.previous_sibling.previous_sibling
#标签树的平行遍历 #遍历后续节点 for sibling in soup.a.next_siblings: print(sibling) #遍历前续节点 for sibling in soup.a.previous_siblings: print(sibling)
基于bs4的html格式化和编码
格式化:
当我们使用soup.prettify()语句时,prettiffy()会给HTML文件加上换行符,使得文件按规则合适输出
我们也可以单独对某一个标签做prettify()处理,比如soup.a.prettify()
编码:
btf-8编码,使用python3就可以保证不用转换。