sigmoid的通俗理解
今天研究了很久的sigmoid,把学习结果总结一下。
sigmoid的二分类问题。
首先我们得有个样本,比如书上的例子。通过人的体重和年龄,来预测血脂的高低。那么数据形式就是[weight,age],血脂的高低用1和0表示,1表示高,0表示低。[1]或者[0]
100个样本数据就是[[88,33],[78,25]......], 所对应的结果是[[1],[0].......], 意思是第一个人体重88,年龄33,血脂高(1);第二个人体重78,年龄25,血脂低(0)。
这100个样本的体重和年龄用X表示,血脂高低用Y表示,如果X的分布如下图,那么我们就可以找出一条能大概条例这些点的直线,那么这条直线的函数是:F = W*X+B 。(F并不等于Y)
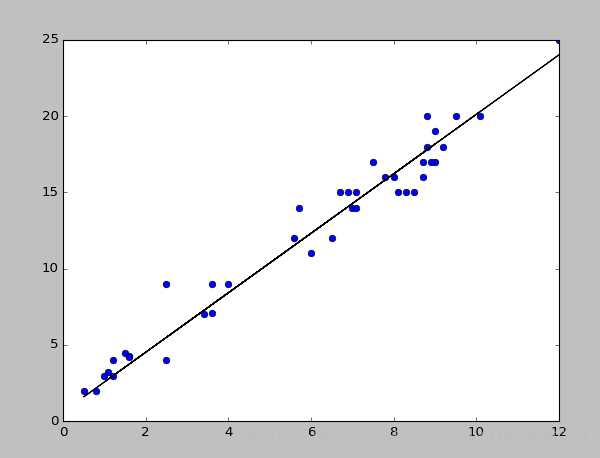
此时,这条直线代表的并不是真实数据。它只是通过100个样本所推算出来,能粗略代表所有人的一个线性方程。(准确性要看样本的大小,样本越大,准确性越高;各个元素之间的相关性越强,准确性也越高)如果此时随便给个新的X,就可以算出它所对应的结果F。
这个F,我们都不知道它代表什么,不重要,我们暂时知道有这个值先。
现在轮到sigmoid出场了!
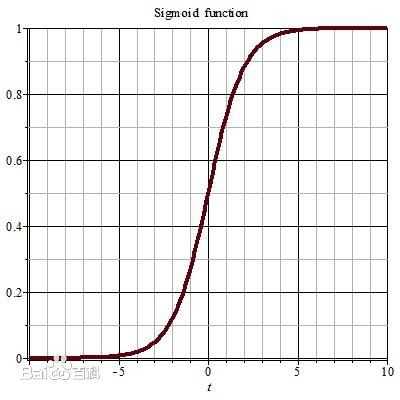
sigmoid的作用是可以把一堆值变成非线性的,它返回值是在0-1之间。当我们将上面得到的F传入sigmoid中(a = tf.sigmoid(F)),sigmoid就会将F的值按照下图的曲线得出a,a是在0-1之间的小数,包括0和1。如果a的值在0.5-1之间,表示血脂高,那么a在0-0.5之间,就表示血脂低。我们是不是直接从100个样本的体重和年龄就可以推算出他们的血脂高低了。对的!就是这样子
第一步:f=tf.matmul(w,x)+b 得出线性方程
第二步:y = tf.sigmoid(f) 将样本分成两类,一类血脂高,一类血脂低。
但是,这个推算出来的分类到底准不准?
文章开头有个数据Y,是100个样本的血脂高低的真实数据。如果我们推算出来的y和真实数据的Y是完全一样的,那准确率就是100%,如果有3个错误,那准确率就是97%,所以我们要通过比较才知道准确率有多少。假设准确率只有56%,我可以通过改变之前那条直线方程的w的值和b的值,得到的F不一样,sigmoid出来的值也不一样,分类也会不同,让它的准确率不断提高,这就叫做优化。
接下来怎么比较?怎么优化呢?
tensorflow有个函数tf.nn.sigmoid_cross_entropy_with_logits(logits=logit,labels=label),这个函数经常用到的参数有两个,一个logits,输入的是未sigmoid的线性方程(F),另一个是labels,这个是真实的数据Y。此函数先对参数logits做sigmoid运算,然后再把运算结果(y)与labels(Y)做交叉熵计算。交叉熵是指推算出来的分类结果(y)与真实数据的分类结果(Y)之间的差异,交叉熵的值越小,两者之间的差异越小。(交叉熵经常用来作损失函数)
高潮来了!!要提高准确率,接近真实数据,是不是只要让交叉熵的值越来越小,就可以了!bingo!!
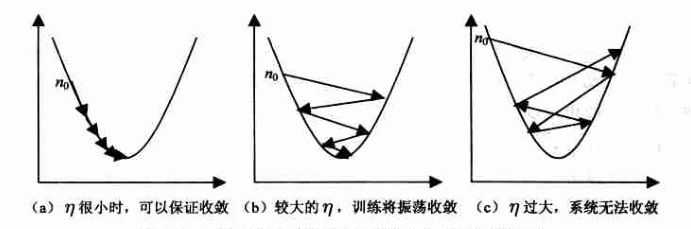
tensorflow里面有个优化器Optimizer,优化器里有个叫梯度下降优化器 tf.train.GradientDescentOptimizer(learn_rate).minimize(loss_fun) 。参数learn_rate是学习率,loss_fun就是要优化的损失函数。学习率自己定个值,如learn_rate=0.01。为了方便理解,可以理解为调节w和b的值,每一次调节0.01,不是调一次就准确了,所以要不停的调,比如循环1000次,直到交叉熵的越来越小,最后稳定在一个值,也就是最小值。这样是结果是最让人满意的,也叫做收敛。如果learn_rate过大,就会无法收敛。(此次梯度暂不展开解释)
此时,我们通过100个样本训练出来的模型就基本定型了。如何还想要继续提高准确率,就要从样本上入手。