SegNet:A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation
论文英文原文网址:https://arxiv.org/abs/1511.00561
SegNet也是图像分割的经典网络,论文的题目可以了解到,SegNet是一个有深度的,带卷积的,同时也自带编码-解码的结构,这个结构主要用于图像分割。SegNet也是一个全卷积神经网络。他的中心结构主要包括:一个编码网络,有编码就有解码,这另一个就是解码网络,解码网络后面又跟着一个像素级的分类层。编码网络的结构与VGG16的13个卷积层的拓扑结构相同。刚开始的编码网络产生低分辨率特征,而解码网络的作用就是将这个粗略的特征映射到整个输入图像级分辨率特征图上用于像素级的分类(此映射必须产生对精确边界定位有用的特征)。作者强调了一小下,SegNet的新颖之处在于解码器上采样其低分辨率输入特征图的方式。这种方式就是解码器通过池化索引来实现非线性的上采样,这个池化索引是由与解码器相对应的编码器进行最大池化操作计算得到的。这就消除了学习上采样的必要,上采样后的maps是稀疏的,然后和可训练的滤波核进行卷积,以产生密集的feature maps。分割后的结果会很粗糙,主要是因为最大池化层和降采样减少了feature maps的分辨率。为了让形状很小的物体也可以被描述出来,要从提取的图像映射中保留边界信息。采用SGD进行训练,因为可以进行end-to-end训练可以一起调节网络的所有权重。前面提到SegNet的编码网络与VGG16中的13个卷积层相同,由于阉割掉了VGG的全连接层,使SegNet的网络要比其他网络小许多,更容易进行训练。SegNet的一个关键component是解码网络,这个有层次的网络与编码网络相对应,前面也说过,解码器使用从与之对应的编码器得到的最大池化索引来对输入的特征图进行非线性上采样。这个想法受到了一个为无监督进行特征学习的结构的启发。在解码过程中重使用最大池化索引有几个接地气的优点:一是改善了边界的划定,二是减少了进行end-to-end训练的参数,因为共用相应池化层的参数,最后一个是这种形式的上采样可以合并到任何encoder-decoder中。在用于分割的深度框架里具有相同的编码网络同时训练参数量也是巨大的,即VGG16,不同点主要体现在解码网络的训练和推理中。
作者在主要是对SegNet解码技术和FCN的分析,关注分割结构设计的实际权衡。作者提到最近用于分割的深度框架都有自己的编码网络,像VGG16,但是其解码网络的训练和推理上却有所不同。由于要训练的网络参数太多,训练网络较为困难,这就导致出现了多阶段训练,将网络加到预先训练好的架构中(像FCN),用RPN,非相交分类训练,和分割网络以及预训练过的额外的训练数据又或者进行全训练等方法进行辅助推理一波。
作者总结了一些分割的前世和今生,今天在这里记录一下,在深度神经网络出现之前,最好的方法是对每个要分类的像素进行手工特征设计。经典的,像随机森林或者Boosting那样通过将一个patch送到分类器中从而预测每个中心像素的类别概率,
来自每个像素级噪声的预测,通过使用成对或更高阶的CRF来进行平滑以提高其准确度。前面提到过是通过预测patch,基于外形的特征或者是基于SfM(SFM算法是一种基于各种收集到的无序图片进行三维重建的离线算法 参考:https://blog.csdn.net/qq_20791919/article/details/74936438)处理后的外观已经在道路场景理解测试中进行探索。
来自分类器的对每个像素噪声的预测通过使用成对或者更高级别的CRF(条件随机场)来进行平滑以提高精度。更近的方法是通过尝试预测patch中所有像素的标签而不仅仅是只预测中心像素的标签来生成高质量的unary(个人感觉这个unary翻译过来就问单元)。虽然改善了基于的随机森林的unaries结果,但是精简结构后的类别分的效果较差。另一种方法是主张利用手工设计的特征和时空超像素的组合来获得更高的准确率。CamVid测试中最好的方法通过在CRF框架中将对象检测输出与分类器预测相结合从而解决标签之间频率不平衡问题。作者提到了室内RGBD数据集,使用的方法为RGB-SIFT,深度SIFT和像素位置等作为神经网络分类器的输入,然后接一个CRF进行平滑,通过使用LBP和区域分割在内的更丰富的特征集合进行改进,从而获得更高的准确性。在最近的工作中,使用RGB和基于深度cues的组合来推断出类别分割和支持关系。另一种方式侧重于实时的进行联合重建和语义分割,随机森林被用作分类器(随机森林真心很强大),在进行类别的分割之前使用边界检测和分层分组。上述这些方法的共同特征是使用手工设计的特征来对RGB或RGBD图像进行分类。
用分类网络中最深一层的特征来匹配图像尺寸应用于图像的分割,但是产生的分类结果是块状的。另一种是使用普通的 神经网络合并几个低分辨率的预测chaung,另一种使用循环神经网络合并几个低分辨率的预测来创建输入图片的分辨率预测图,其划定边界的能力很差。
用于分割的新的框架结构通过学习解码或者将低分辨率图像映射为像素级的预测来应用于分割。其中,产生低分辨率图像的表示的编码网络是VGG16分类网络,有13个卷积层和3个全连接层。不同结构的解码网络有所不同,并为每个像素产生多个特征以用于接下来的分类。
FCN中的每个解码器学习对输入的特征映射进行上采样,并将他们与相应的编码器的feature map进行组合作为下一个解码器的输入。这种结构的特点是编码网络中有大量的可训练的参数,而解码网络的却很少。此网络的整体规模很大,很难进行end-to-end训练。所以,作者使用分段式训练处理,解码网络中的每个解码器都被逐个的添加到训练网络中,网络不会一直增加,如果观察的性能没有增加则停止。网络的增长在三个解码器之后就会停止,如果忽略高分辨率的feature map就会导致边缘信息的丢失。上面是有关训练的问题,在编码器中重新使用编码器产生的feature map会在测试时时内存比较拥挤。
在RNN上外加FCN进行微调实现,在利用FCN的特征表示时,RNN层模仿CRF的清晰的边界描绘能力。与FCN-8相比,前面的结构有着显著的改进,随着数据的增多,这种改进也不大。FCN+CRF-RNN这种结构在进行联合训练时体现出了优势,虽然以更复杂的训练和推理为代价,去卷积网络的性能要明显优于FCN。这里作者提出一个疑问,就是随着前馈分割engine变得更好,CRF-RNN的感知优势是否会降低。在任何条件下,CRF-RNN网络都可以加到包括SegNet的任何分段体系结构中。作者提到过多尺寸的深层结构也是比较流行的。有两种风格,一是结合来自深层特征提取网络的少量尺寸的输入图像,另一种是结合来自单一深层架构的不同层的feature maps。常见的思路就是进行不同尺寸的特征提取,从而提供局部或全局的上下文,同时,早期编码层使用的feature maps保留了更多的高频率细节,从而是类边界更加清晰。为了使训练更易进行,采用多阶段训练和数据增强一起使用,用多个卷积路径推理进行特征提取是十分昂贵的。将CRF添加到多尺寸网络进行联合训练。反卷积网络及其半监督的变体形式,使用的是编码器的feature maps在解码网络中实现非线性上采样。
作者提出的网络结构是编码-解码网络,编码器是由卷积,非线性单元,最大池化以及降采样来获得feature maps。对于每个样本,池中计算的最大位置索引被存储到解码器中。解码器通过存储中的索引来对feature maps进行上采样操作。解码网络使用可训练的卷积核与上采样的feature map卷积用于重建输入图像。这种结构用于无监督前的预训练,通过使用小的输入patch进行分层特征的学习从而能够将整幅图用于分层编码器的学习。
SegNet的网络结构
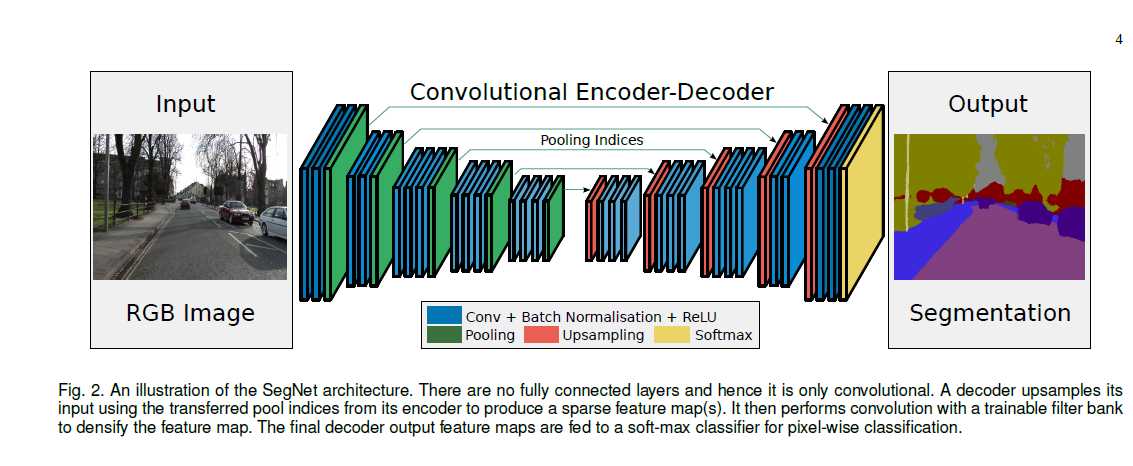
SegNet有编码网络和相对应的解码网络,其后是最终的像素级分类层。编码网络由13个卷积层组成,他们对应于VGG16中的前13个卷积层,用于对物体的分了。作者使用初始化训练过程,使用经过训练的权重对大数据集进行分类。SegNet将全连接层去除(某种程度上也减少了网络的参数的数量),目的是在最深的编码器输出端保留更高分辨率的feature maps。在编码网络中每个编码器进行卷积从而产生一组feature maps。这些feature maps会被进行标准化处理,然后应用ReLU进行处理。然后进行大小2*2,步长为2的最大池化操作,将结果进行二倍降采样。最大池化操作用于实现输入图像中小空间位移的平移不变性。降采样会产生feature map中每个像素在一个输入图像的上下文信息。多层最大池化和降采样可以实现更多的平移不变性从而使分类更加鲁棒,但对feature maps 上的空间分辨率仍有一定损失。对边界细节有损的图像表示不利于分割(对边界划分很重要的分割)。因此,需要在进行降采样前对编码器中feature map捕获并存储边界信息。要对所有的feature map进行存储是不可能的,只存储每个编码器feature map的每个池化窗口中最大特征值的位置。解码网络中的适当解码器通过利用来自对应的编码网络feature map中存储的最大池化索引值对输入的feature map进行上采样。从而得到稀疏的特征图。SegNet的解码过程如下图,
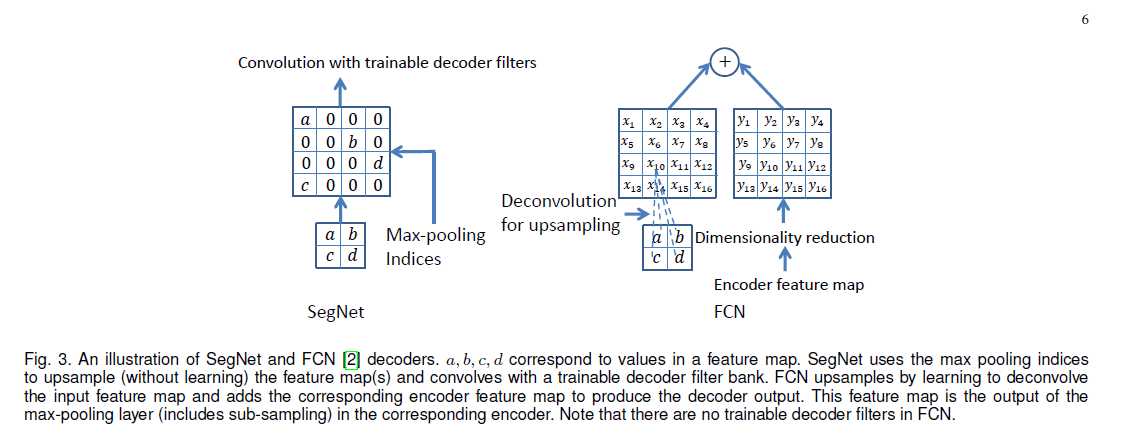
图中也说了,解码后的feature map还要进行卷积操作从而生成密集的feature maps然后进行批标准化处理。这里与常识不同,虽然编码器输入由RGB3个通道,但是与第一个编码器对应的解码器会生成多通道的feature map,这个与网络中的其他编码器不同(其他的解码器能够产生和编码器输入相同数量的大小和通道的feature maps)。最后一个解码器输出的高维特征表示被送到可训练的softmax分类器,用于分割每个独立的像素。DeconvNet和Unet具有与SegNet相似的结构。但由于DeconvNet具有全卷积,有大量的参数,从而难以进行end-to-end的训练。而Unet无法重复使用池化的 索引,而是将整个feature map转移的对应的解码器中,通过反卷积进行上采样得到解码器的feature map。而且Unet没有VGG中的conv5和max-pool5层。SegNet使用来自VGG所有预先训练的卷积层权重作为预训练的权重。
作者后面提到了一个只有四个encoder 和四个decoder的miniSegNet,其在卷积之后就不在使用bias,在decoder网络中也没有ReLU非线性化处理。所有encoder decoder层的核大小定义为7*7,可以从feature map中获得更多的上下文信息。
具体实验及分析请参考论文原文。