ResNeXt——与 ResNet 相比,相同的参数个数,结果更好:一个 101 层的 ResNeXt 网络,和 200 层的 ResNet 准确度差不多,但是计算量只有后者的一半
from:https://blog.csdn.net/xuanwu_yan/article/details/53455260
背景
论文地址:Aggregated Residual Transformations for Deep Neural Networks
代码地址:GitHub
这篇文章在 arxiv 上的时间差不多是今年 cvpr 截稿日,我们就先理解为是投的 cvpr 2017 吧,作者包括熟悉的 rbg
和何凯明,转战 Facebook 之后代码都放在 Facebook 的主页里面了,代码也从 ResNet 时的 caffe 改成了 torch
:)
贡献
- 网络结构简明,模块化
- 需要手动调节的超参少
- 与 ResNet 相比,相同的参数个数,结果更好:一个 101 层的 ResNeXt 网络,和 200 层的 ResNet 准确度差不多,但是计算量只有后者的一半
方法
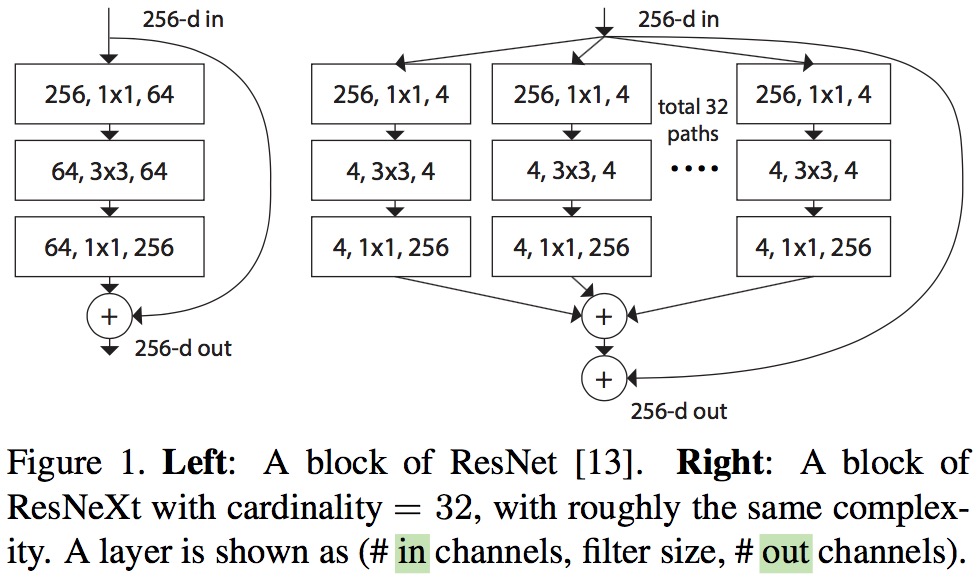
提出来 cardinality 的概念,在上图左右有相同的参数个数,其中左边是 ResNet 的一个区块,右边的 ResNeXt 中每个分支一模一样,分支的个数就是 cardinality。此处借鉴了 GoogLeNet 的 split-transform-merge,和 VGG/ResNets 的 repeat layer。
所谓 split-transform-merge 是指通过在大卷积核层两侧加入 1x1 的网络层,控制核个数,减少参数个数的方式。借鉴 fei-fei li 的 cs231n 课件1:

而 repeat layer 则是指重复相同的几层,前提条件是这几层的输出输出具有相同的维度,一般在不同的 repeat layers 之间使用 strip=2 降维,同时核函数的个数乘 2。
本文网络参数
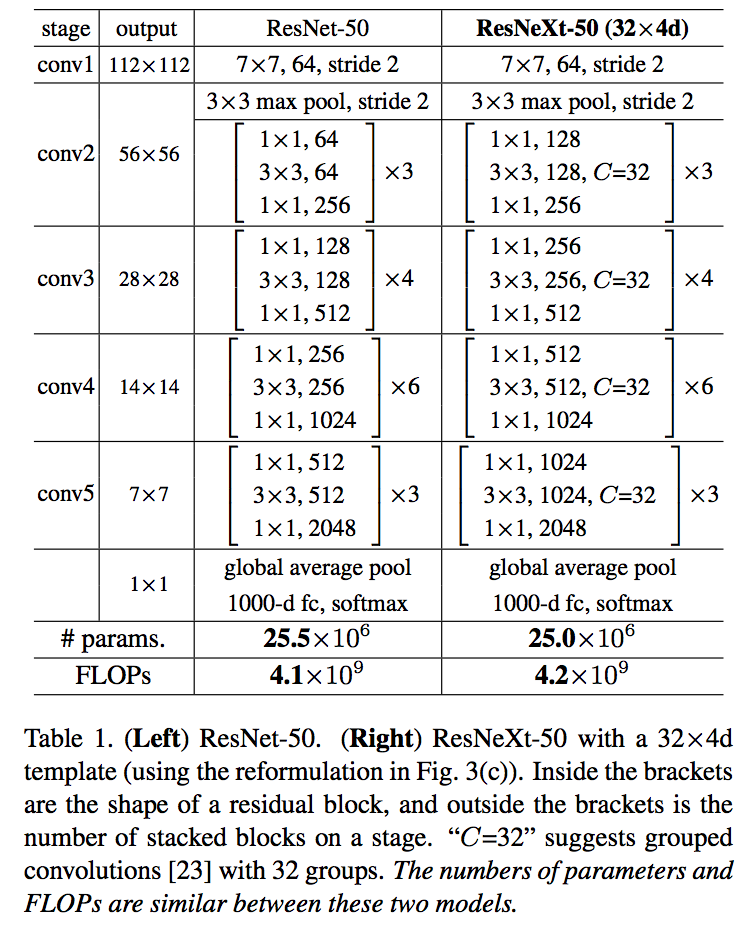
以上图为例,中括号内就是 split-transform-merge,通过 cardinality(C) 的值控制 repeat layer。
output 在上下相邻的格子不断减半,中括号内的逗号后面卷积核的个数不断翻倍。
等价模式
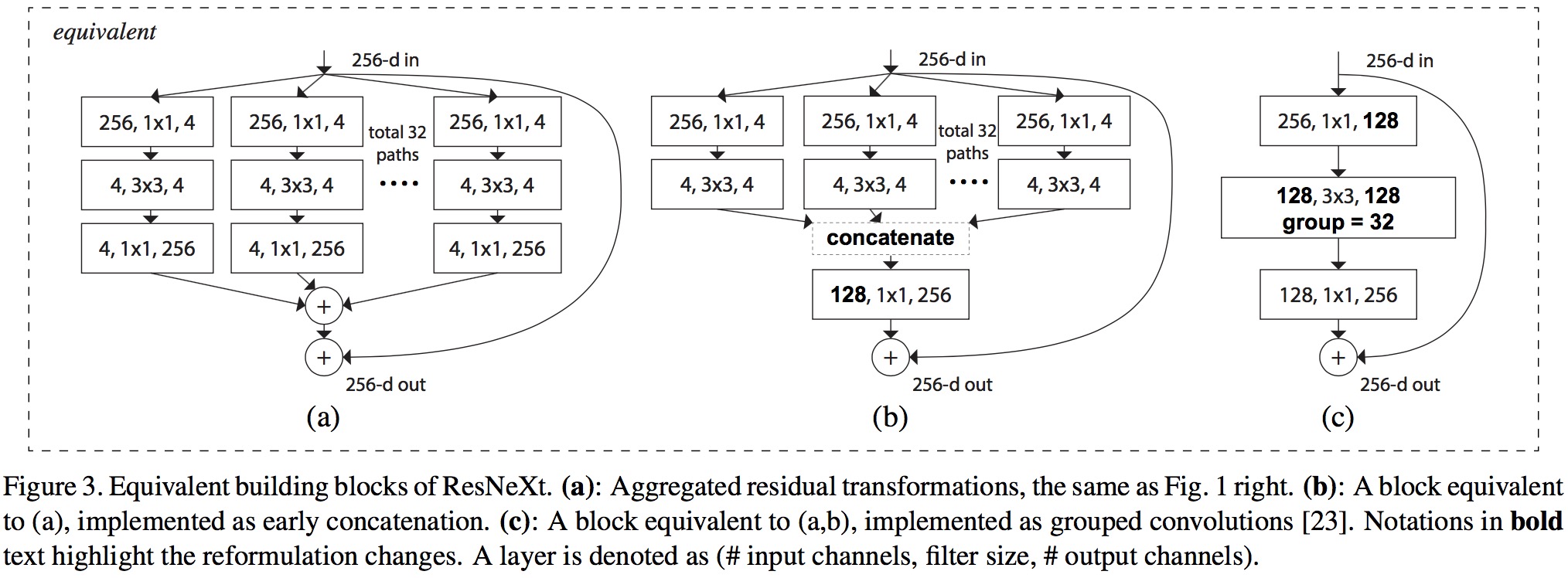
图一右侧的模型有两个等价的模型,最右侧是 AlexNet 中提出的分组卷积,相同层的 width 分组卷积,最终作者使用的是下图最右边的模型,更加简洁并且训练更快。
模型参数
调节 cardinality 时,如何保证和 ResNet 的参数个数一致呢?本文考虑的是调节 split-transform-merge 中间第二层卷积核的个数。
实验
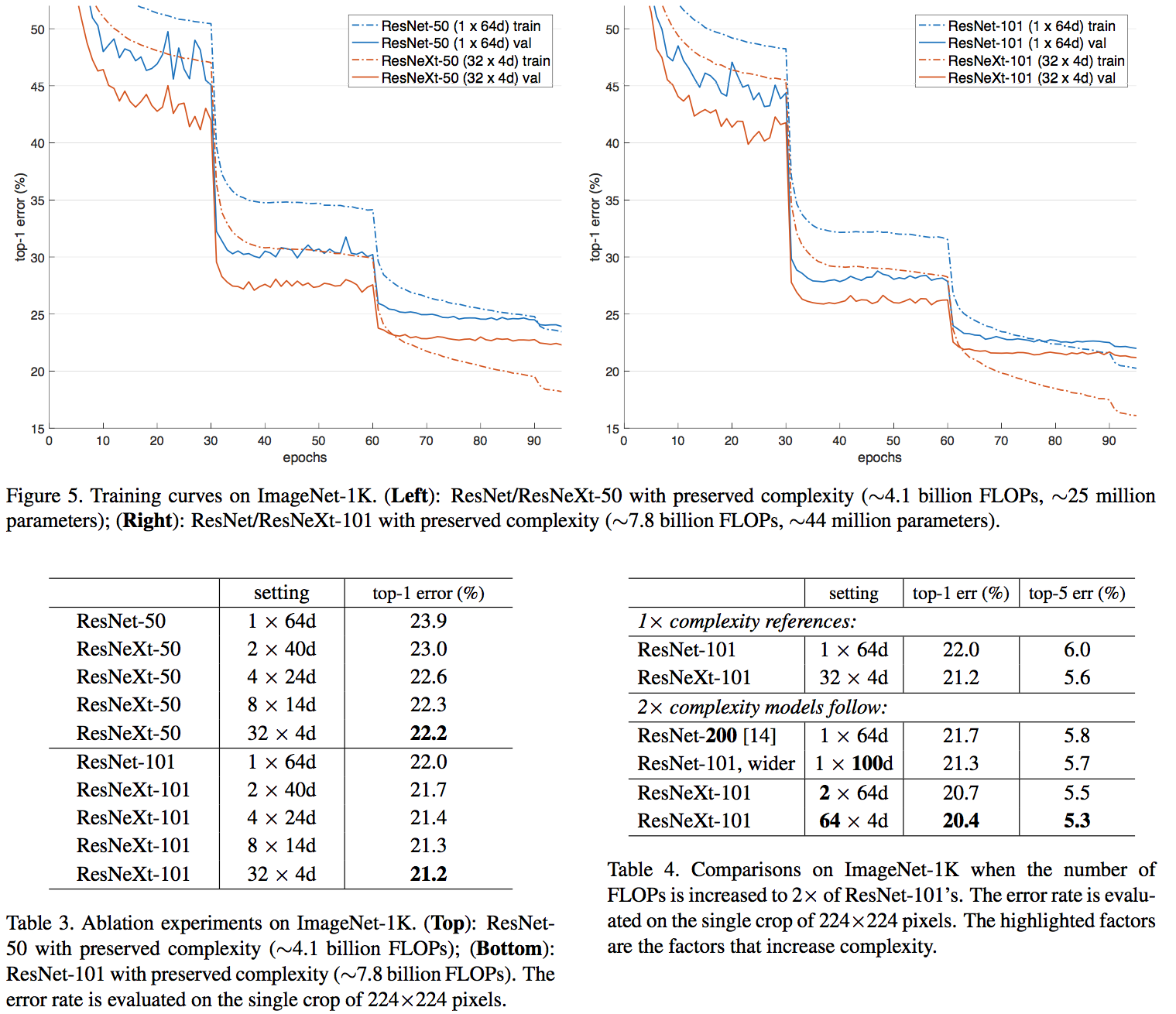
基本和 ResNet 差不多,augmentation、以及各个参数
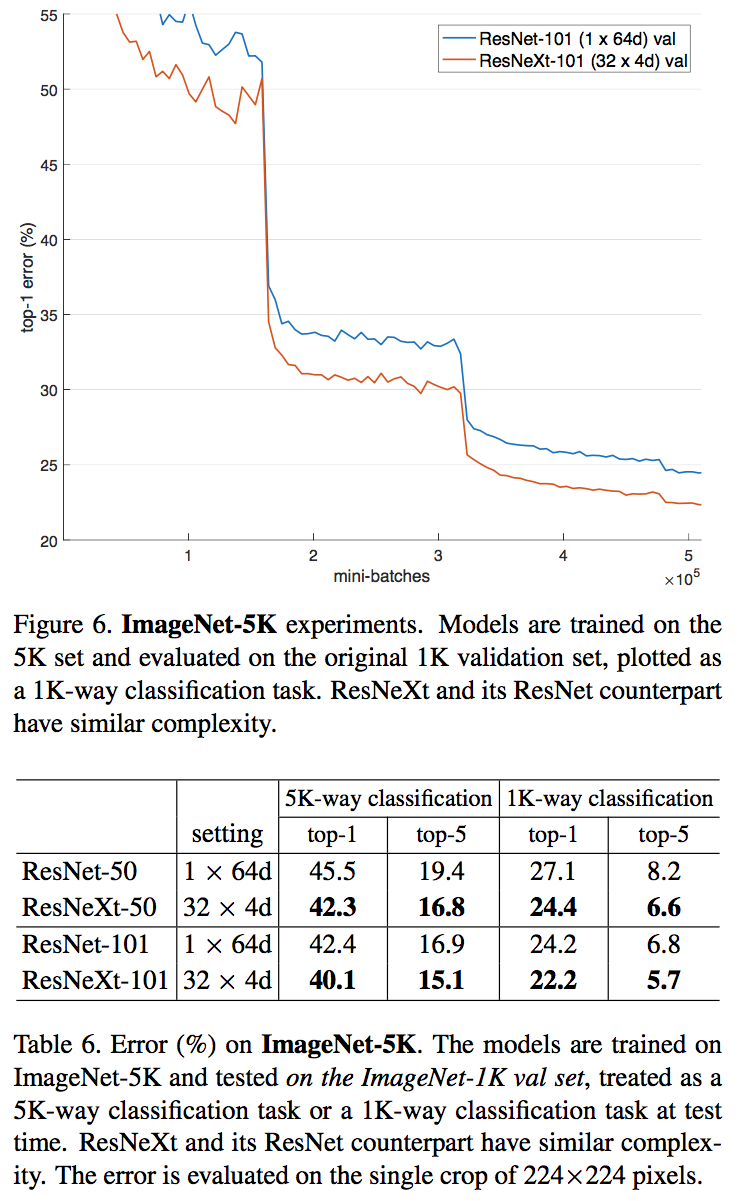
结论
- ResNeXt 与 ResNet 在相同参数个数情况下,训练时前者错误率更低,但下降速度差不多
- 相同参数情况下,增加 cardinality 比增加卷几个数更加有效
- 101 层的 ResNeXt 比 200 层的 ResNet 更好
- 几种 sota 的模型,ResNeXt 准确率最高
深度学习——分类之ResNeXt
论文:Aggregated Residual Transformations for Deep Neural Networks
作者:Saining Xie, Ross Girshick, Piotr Dollár, Zhuowen Tu, Kaiming He
ImageNet Top5错误率:3.03%
中心思想:Inception那边把ResNet拿来搞了Inception-ResNet,这头ResNet也把Inception拿来搞了一个ResNeXt,主要就是单路卷积变成多个支路的多路卷积,不过分组很多,结构一致,进行分组卷积。
卷积的范式
作者一上来先归纳了Inception的模式:split-transform-merge。
如下图所示,先将输入分配到多路,然后每一路进行转换,最后再把所有支路的结果融合。
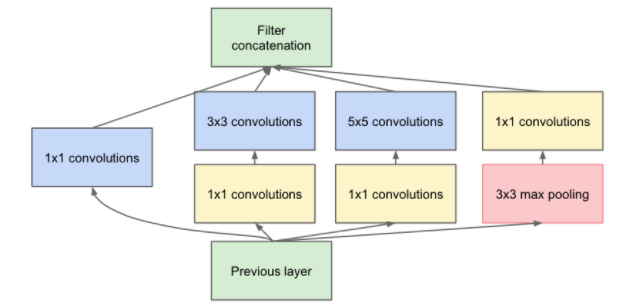
少不了要提一下Inception的缺点,太复杂了,人工设计的痕迹太重了。
然后,站得更高,分析了神经网络的标准范式就符合这样的split-transform-merge模式。以一个最简单的普通神经元为例(比如FC中的每个神经元):
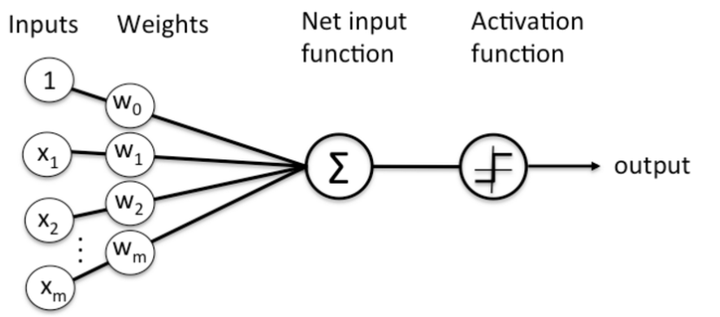
就是先对输入的m个元素,分配到m个分支,进行权重加权,然后merge求和,最后经过一个激活。
由此归纳出神经网络的一个通用的单元可以用如下公式表示:
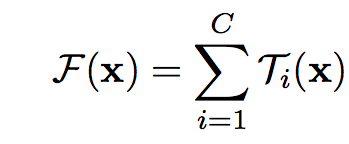
结合ResNet的identity映射,带residual的结构可以用如下公式表示:
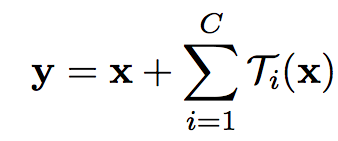
上面的变换T可以是任意形式,一共有C个独立的变换,作者将C称之为基数,并且指出,基数C对于结果的影响比宽度和深度更加重要。
基本结构
如下图,左边是ResNet的基本结构,右边是ResNeXt的基本结构:
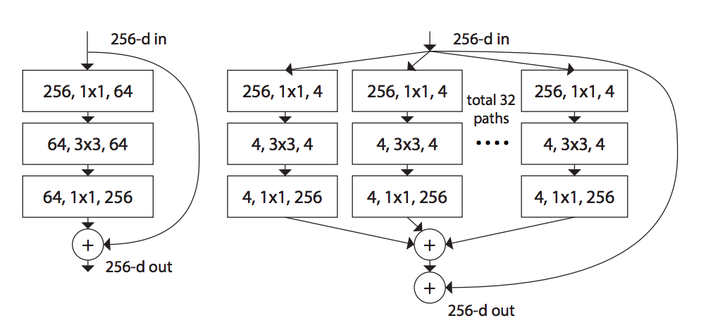
回忆下上面的公式,可以看到,旁边的residual connection就是公式中的x直接连过来,然后剩下的是32组独立的同样结构的变换,最后再进行融合,符合split-transform-merge的模式。
作者进一步指出,split-transform-merge是通用的神经网络的标准范式,前面已经提到,基本的神经元符合这个范式,而如下图所示:
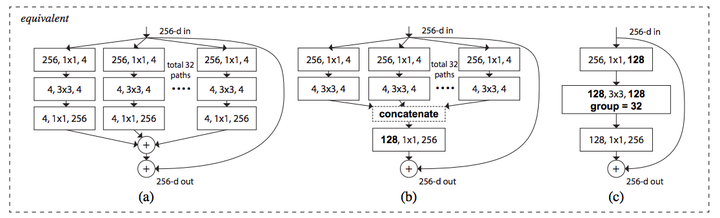
a是ResNeXt基本单元,如果把输出那里的1x1合并到一起,得到等价网络b拥有和Inception-ResNet相似的结构,而进一步把输入的1x1也合并到一起,得到等价网络c则和通道分组卷积的网络有相似的结构。
到这里,可以看到本文的野心很大,相当于在说,Inception-ResNet和通道分组卷积网络,都只是ResNeXt这一范式的特殊形式而已,进一步说明了split-transform-merge的普遍性和有效性,以及抽象程度更高,更本质一点。
ResNeXt
然后是ResNeXt具体的网络结构。
类似ResNet,作者选择了很简单的基本结构,每一组C个不同的分支都进行相同的简单变换,下面是ResNeXt-50(32x4d)的配置清单,32指进入网络的第一个ResNeXt基本结构的分组数量C(即基数)为32,4d表示depth即每一个分组的通道数为4(所以第一个基本结构输入通道数为128):
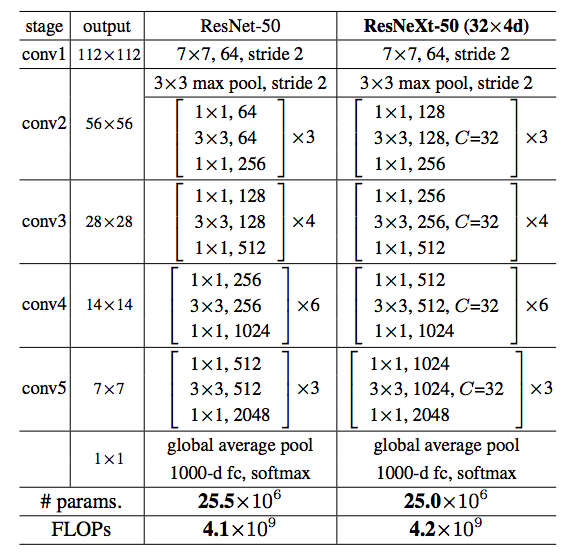
可以看到ResNet-50和ResNeXt-50(32x4d)拥有相同的参数,但是精度却更高。
具体实现上,因为1x1卷积可以合并,就合并了,代码更简单,并且效率更高。
参数量不变,但是效果太好,这个时候通常会有一个『但是』。。。但是,因为分组了,多个分支单独进行处理,所以相交于原来整个一起卷积,硬件执行效率上会低一点,训练ResNeXt-101(32x4d)每个mini-batch要0.95s,而ResNet-101只要0.70s,虽然本质上计算量是相同的,通过底层的优化因为能缩小这个差距。好消息是,看了下最近的cuDNN7的更新说明:
Grouped Convolutions for models such as ResNeXt and Xception and CTC (Connectionist Temporal Classification) loss layer for temporal classification
貌似已经针对分组卷积进行了优化,我还没进行过测试,不过我猜效率应该提升了不少。
至于具体的效果,ResNeXt-101(32x4d)大小和Inception v4相当,效果略差,但Inception-v4慢啊= =,ResNeXt-101(64x4d)比Inception-Resnet v2要大一点,精度相当或略低。
上面的比较并不算很严谨,和训练方式、实现方式等有很大的关系,实际使用中区别不大,还没有找到一个很全的benchmark可以准确比较。不过这里的结果可以作为一个参考。
得益于精心设计的复杂的网络结构,ResNet-Inception v2可能效果会更好一点,但是ResNeXt的网络结构更简单,可以防止对于特定数据集的过拟合。而且更简单的网络意味着在用于自己的任务的时候,自定义和修改起来更简单。
最后,提一个八卦,ResNet作者的论文被Inception v4那篇argue说residual connection可以提升训练收敛速度,但是对于精度没有太大帮助,然后这篇ResNeXt马上又怼回去了,说没有要降好几个点,对于网络的优化是有帮助的。。。
总结下:split-transform-merge模式是作者归纳的一个很通用的抽象程度很高的标准范式,然后ResNeXt就这这一范式的一个简单标准实现,简洁高效啊。