第二十一节,使用TensorFlow实现LSTM和GRU网络
本节主要介绍在TensorFlow中实现LSTM以及GRU网络。
关于LSTM的详细内容推荐阅读以下博客:
一 LSTM网络
Long Short Term 网络—— 一般就叫做 LSTM ——是一种 RNN 特殊的类型,可以学习长期依赖信息。LSTM 由 Hochreiter & Schmidhuber (1997) 提出,并在近期被 Alex Graves 进行了改良和推广。在很多问题,LSTM 都取得相当巨大的成功,并得到了广泛的使用。
LSTM 通过刻意的设计来避免长期依赖问题。记住长期的信息在实践中是 LSTM 的默认行为,而非需要付出很大代价才能获得的能力!
LSTM的结构如下:
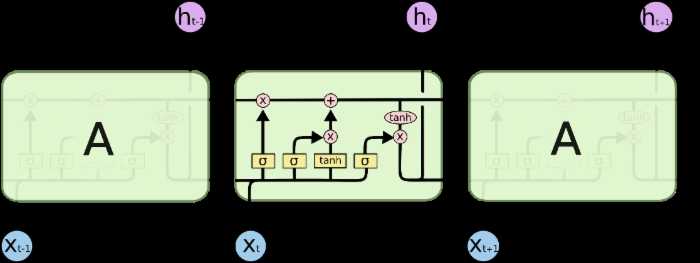
这种结构的核心思想是引入了一个叫做细胞状态的连接,这个细胞状态用来存放想要记忆的东西。同时在里面加入了三个门:
- 忘记门;顾名思义,是控制是否遗忘的,在LSTM中即以一定的概率控制是否遗忘上一层的隐藏细胞状态。
- 输入门:输入门(input gate)负责处理当前序列位置的输入.
- 输出门:决定什么时候需要把状态和输出放在一起输出。
二 LSTM 的变体
上面我们介绍了正常的 LSTM。但是不是所有的 LSTM 都长成一个样子的。实际上,几乎所有包含 LSTM 的论文都采用了微小的变体。差异非常小,但是也值得拿出来讲一下。
1.窥视孔连接(peephole )
其中一个流形的 LSTM 变体,就是由 Gers & Schmidhuber (2000) 提出的,增加了 “peephole connection”。是说,我们让 门层 也会接受细胞状态的输入。

上面的图例中,我们增加了 peephole 到每个门上,但是许多论文会加入部分的 peephole 而非所有都加。
2.oupled 忘记门和输入门
另一个变体是通过使用 coupled 忘记和输入门。不同于之前是分开确定什么忘记和需要添加什么新的信息,这里是一同做出决定。我们仅仅会当我们将要输入在当前位置时忘记。我们仅仅输入新的值到那些我们已经忘记旧的信息的那些状态 。

3.GRU
另一个改动较大的变体是 Gated Recurrent Unit (GRU),这是由 Cho, et al. (2014) 提出。它将忘记门和输入门合成了一个单一的 更新门。同样还混合了细胞状态和隐藏状态,和其他一些改动。最终的模型比标准的 LSTM 模型要简单,也是非常流行的变体。由于GRU比LSTM少了一个状态输出,效果几乎一样,因此在编码使用时使用GRU可以让代码更为简单一些。

这里只是部分流行的 LSTM 变体。当然还有很多其他的,如 Yao, et al. (2015) 提出的 Depth Gated RNN。还有用一些完全不同的观点来解决长期依赖的问题,如 Koutnik, et al. (2014) 提出的 Clockwork RNN。
要问哪个变体是最好的?其中的差异性真的重要吗? Greff, et al. (2015) 给出了流行变体的比较,结论是他们基本上是一样的。 Jozefowicz, et al. (2015) 则在超过 1 万中 RNN 架构上进行了测试,发现一些架构在某些任务上也取得了比 LSTM 更好的结果。
三 Bi-RNN网络介绍
Bi-RNN又叫双向RNN,是采用了两个方向的RNN网络。
RNN网络擅长的是对于连续数据的处理,既然是连续的数据规律,我们不仅可以学习他的正向规律,还可以学习他的反向规律。这样正向和反向结合的网络,回比单向循环网络有更高的拟合度。
双向RNN的处理过程和单向RNN非常相似,就是在正向传播的基础上再进行一次反向传播,而且这两个都连接这一个输出层。
四 TensorFlow中cell库
TensorFlow中定义了5个关于cell的类,cell我们可以理解为DNN中的一个隐藏层,只不过是一个比较特殊的层。如下
1.BasicRNNCell类
最基本的RNN类实现:
def __init__(self, num_units, activation=None, reuse=None)
- num_units:LSTM网络单元的个数,也即隐藏层的节点数。
- activation: Nonlinearity to use. Default: `tanh`.
- reuse:(optional) Python boolean describing whether to reuse variables in an existing scope. If not `True`, and the existing scope already has the given variables, an error is raised.
2.BasicLSTMCell类
LSTM网络:
def __init__(self, num_units, forget_bias=1.0, state_is_tuple=True, activation=None, reuse=None):
- num_units:LSTM网络单元的个数,也即隐藏层的节点数。
- forget_bias:添加到忘记门的偏置。
- state_is_tuple:由于细胞状态ct和输出ht是分开的,当为True时放在一个tuple中,(c=array([[]]),h=array([[]])),当为False时两个值就按列连接起来,成为[batch,2n],建议使用True。
- activation: Activation function of the inner states. Default: `tanh`.
- reuse: (optional) Python boolean describing whether to reuse variables in an existing scope. If not `True`, and the existing scope already has the given variables, an error is raised. 在一个scope中是否重用。
3.LSTMCell类
LSTM实现的一个高级版本。
def __init__(self, num_units, use_peepholes=False, cell_clip=None, initializer=None, num_proj=None, proj_clip=None, num_unit_shards=None, num_proj_shards=None, forget_bias=1.0, state_is_tuple=True, activation=None, reuse=None):
- num_units:LSTM网络单元的个数,也即隐藏层的节点数。
- use_peepholes:默认False,True表示启用Peephole连接。
- cell_clip:是否在输出前对cell状态按照给定值进行截断处理。
- initializer: (optional) The initializer to use for the weight and projection matrices.
- num_proj: (optional) int, The output dimensionality for the projection matrices. If None, no projection is performed.通过projection层进行模型压缩的输出维度。
- proj_clip: (optional) A float value. If `num_proj > 0` and `proj_clip` is provided, then the projected values are clipped elementwise to within `[-proj_clip, proj_clip]`.将num_proj按照给定的proj_clip截断。
- num_unit_shards: Deprecated, will be removed by Jan. 2017. Use a variable_scope partitioner instead.
- num_proj_shards: Deprecated, will be removed by Jan. 2017. Use a variable_scope partitioner instead.
- forget_bias: Biases of the forget gate are initialized by default to 1 in order to reduce the scale of forgetting at the beginning of the training.
- state_is_tuple: If True, accepted and returned states are 2-tuples of the `c_state` and `m_state`. If False, they are concatenated along the column axis. This latter behavior will soon be deprecated.
- activation: Activation function of the inner states. Default: `tanh`.
- reuse: (optional) Python boolean describing whether to reuse variables in an existing scope. If not `True`, and the existing scope already has the given variables, an error is raised.
4.GRU类
def __init__(self, num_units, activation=None, reuse=None, kernel_initializer=None, bias_initializer=None):
- num_units:GRU网络单元的个数,也即隐藏层的节点数。
- activation: Nonlinearity to use. Default: `tanh`.
- reuse:(optional) Python boolean describing whether to reuse variables in an existing scope. If not `True`, and the existing scope already has the given variables, an error is raise
5.MultiRNNCell
多层RNN的实现:
def __init__(self, cells, state_is_tuple=True)
- cells: list of RNNCells that will be composed in this order. 一个cell列表。将列表中的cell一个个堆叠起来,如果使用cells=[cell1,cell2],就是一共有2层,数据经过cell1后还要经过cells。
- state_is_tuple: If True, accepted and returned states are n-tuples, where `n = len(cells)`. If False, the states are all concatenated along the column axis. This latter behavior will soon be deprecated.如果是True则返回的是n-tuple,即cell的输出值与cell的输出状态组成了一个元组。其中输出值和输出状态的结构均为[batch,num_units]。
五 通过cell类构建RNN
定义好cell类之后,还需要将它们连接起来构成RNN网络,TensorFlow中有几种现成的构建网络模式,是封装好的函数,直接调用即可:
1.静态RNN构建
def tf.contrib.rnn.static_rnn(cell, inputs, initial_state=None, dtype=None, sequence_length=None, scope=None):
- cell:生成好的cell类对象。
- inputs:A length T list of inputs, each a `Tensor` of shape `[batch_size, input_size]`, or a nested tuple of such elements.输入数据,由张量组成的list。list的顺序就是时间顺序。元素就是每个序列的值,形状为[batch_size,input_size]。
- initial_state: (optional) An initial state for the RNN. If `cell.state_size` is an integer, this must be a `Tensor` of appropriate type and shape `[batch_size, cell.state_size]`. If `cell.state_size` is a tuple, this should be a tuple of tensors having shapes `[batch_size, s] for s in cell.state_size`.初始化cell状态。
- dtype: (optional) The data type for the initial state and expected output. Required if initial_state is not provided or RNN state has a heterogeneous。期望输出和初始化state的类型。
- sequence_length: Specifies the length of each sequence in inputs. An int32 or int64 vector (tensor) size `[batch_size]`, values in `[0, T)`.每一个输入的序列长度。
- scope: VariableScope for the created subgraph; defaults to "rnn".命名空间
返回值有两个,一个是输出结果,一个是cell状态。我们只关注结果,结果也是一个list,输入是多少个时序,list里面就会有多少个元素。每个元素大小为[batch_size,num_units]。
注意:在输入时,一定要将我们习惯使用的张量改为由张量组成的list。另外,在得到输出时也要去最后一个时序的输出参与后面的运算。
2.动态RNN构建
def tf.nn.dynamic_rnn(cell, inputs, sequence_length=None,
initial_state=None, dtype=None, parallel_iterations=None,
swap_memory=False, time_major=False, scope=None):
- cell:生成好的cell类对象。
- inputs:If `time_major == False` (default), this must be a `Tensor` of shape:`[batch_size, max_time, ...]`, or a nested tuple of such elements. If `time_major == True`, this must be a `Tensor` of shape: `[max_time, batch_size, ...]`, or a nested tuple of such elements. 输入数据,是一个张量,默认是三维张量,[batch_size,max_time,...],batch_size表示一个批次数量,max_time:表示时间序列总数,后面是一个时序输入数据的长度。
- sequence_length: Specifies the length of each sequence in inputs. An int32 or int64 vector (tensor) size `[batch_size]`, values in `[0, T)`.每一个输入的序列长度。
- initial_state: (optional) An initial state for the RNN.If `cell.state_size` is an integer, this must be a `Tensor` of appropriate type and shape `[batch_size, cell.state_size]`. If `cell.state_size` is a tuple, this should be a tuple of tensors having shapes `[batch_size, s] for s in cell.state_size`.初始化cell状态。
- dtype:期望输出和初始化state的类型。
- parallel_iterations: (Default: 32). The number of iterations to run inparallel. Those operations which do not have any temporal dependency and can be run in parallel, will be. This parameter trades off time for space. Values >> 1 use more memory but take less time, while smaller values use less memory but computations take longer.
- swap_memory: Transparently swap the tensors produced in forward inference but needed for back prop from GPU to CPU. This allows training RNNs which would typically not fit on a single GPU, with very minimal (or no) performance penalty.
- time_major: The shape format of the `inputs` and `outputs` Tensors. If true, these `Tensors` must be shaped `[max_time, batch_size, depth]`. If false, these `Tensors` must be shaped `[batch_size, max_time, depth]`. Using `time_major = True` is a bit more efficient because it avoids transposes at the beginning and end of the RNN calculation. However, most TensorFlow data is batch-major, so by default this function accepts input and emits output in batch-major form.
- scope: VariableScope for the created subgraph; defaults to "rnn".命名空间。
返回值:一个是结果,一个是cell状态。
A pair (outputs, state) where:
outputs: The RNN output `Tensor`.
If time_major == False (default), this will be a `Tensor` shaped: `[batch_size, max_time, cell.output_size]`.
If time_major == True, this will be a `Tensor` shaped: `[max_time, batch_size, cell.output_size]`.
Note, if `cell.output_size` is a (possibly nested) tuple of integers or `TensorShape` objects, then `outputs` will be a tuple having the same structure as `cell.output_size`, containing Tensors having shapes
corresponding to the shape data in `cell.output_size`.
state: The final state. If `cell.state_size` is an int, this will be shaped `[batch_size, cell.state_size]`. If it is a `TensorShape`, this will be shaped `[batch_size] + cell.state_size`. If it is a (possibly nested) tuple of ints or `TensorShape`, this will be a tuple having the corresponding shapes.
由于time_major默认值是False,所以结果是以[batch_size,max_time,...]形式的张量。
注意:在输出时如果是以[batch_size,max_time,...]形式,即批次优先的矩阵,因为我们需要取最后一个时序的输出,所以需要转置成时间优先的形式。
outputs = tf.transpose(outputs,[1,0,2])
3.双向RNN构建
双向RNN作为一个可以学习正反规律的循环神经网络,在TensorFlow中有4个函数可以使用。