Docx4j将html转成word时,br标签为软回车的问题修改
docx4j版本:3.0.1
修改jar包:docx4j-ImportXHTML
maven配置为: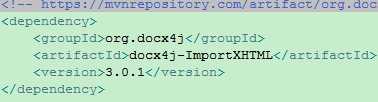
具体代码位置:\org\docx4j\convert\in\xhtml\XHTMLImporterImpl.java 中 processInlineBoxContent方法
代码修改前: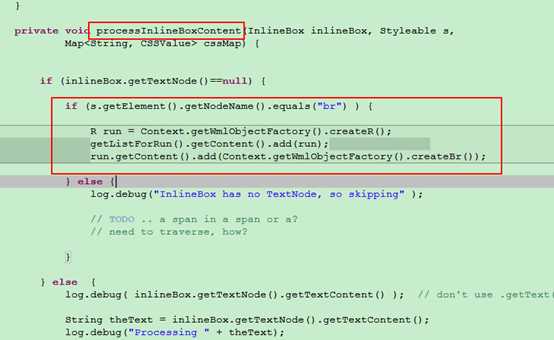
代码修改后: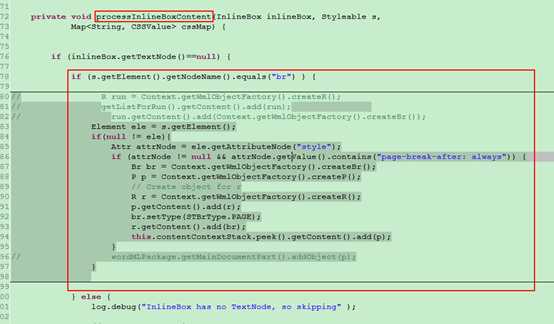
private void processInlineBoxContent(InlineBox inlineBox, Styleable s,
Map<String, CSSValue> cssMap) {
if (inlineBox.getTextNode()==null) {
if (s.getElement().getNodeName().equals("br") ) {
// R run = Context.getWmlObjectFactory().createR();
// getListForRun().getContent().add(run);
// run.getContent().add(Context.getWmlObjectFactory().createBr());
Element ele = s.getElement();
if(null != ele){
Attr attrNode = ele.getAttributeNode("style");
if (attrNode != null && attrNode.getValue().contains("page-break-after: always")) {
Br br = Context.getWmlObjectFactory().createBr();
P p = Context.getWmlObjectFactory().createP();
// Create object for r
R r = Context.getWmlObjectFactory().createR();
p.getContent().add(r);
br.setType(STBrType.PAGE);
r.getContent().add(br);
this.contentContextStack.peek().getContent().add(p);
}
// wordMLPackage.getMainDocumentPart().addObject(p);
}
} else {
log.debug("InlineBox has no TextNode, so skipping" );
// TODO .. a span in a span or a?
// need to traverse, how?
}
} else {
log.debug( inlineBox.getTextNode().getTextContent() ); // don‘t use .getText()
String theText = inlineBox.getTextNode().getTextContent();
log.debug("Processing " + theText);
paraStillEmpty = false;
String cssClass = getClassAttribute(s.getElement());
if (cssClass!=null) {
cssClass=cssClass.trim();
}
addRun(cssClass, cssMap, theText);
// else {
// // Get it from the parent element eg p
// //Map cssMap = styleReference.getCascadedPropertiesMap(e);
// run.setRPr(
// addRunProperties( cssMap ));
// }
}
}
文章来自:http://www.cnblogs.com/Iqiaoxun/p/7019331.html