Python图片识别——人工智能篇
一、安装pytesseract和PIL
PIL全称:Python Imaging Library,python图像处理库,这个库支持多种文件格式,并提供了强大的图像处理和图形处理能力。
由于PIL仅支持到Python 2.7,所以在PIL的基础上创建了Pillow库,支持最新Python 3.x。
1、pip命令安装
pip install pytesseract
pip install Pillow
2、使用pycharm编辑器安装,如下操作步骤。
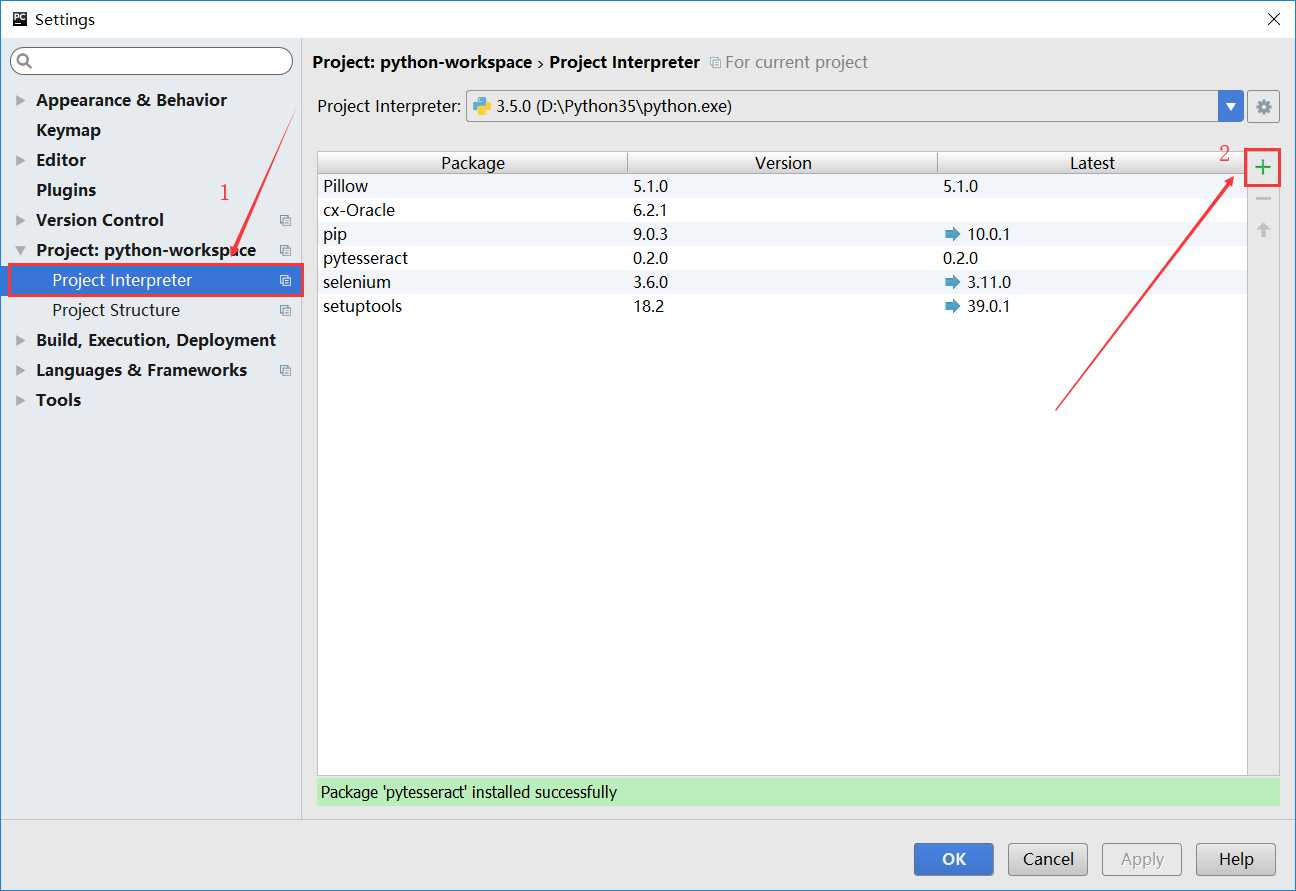
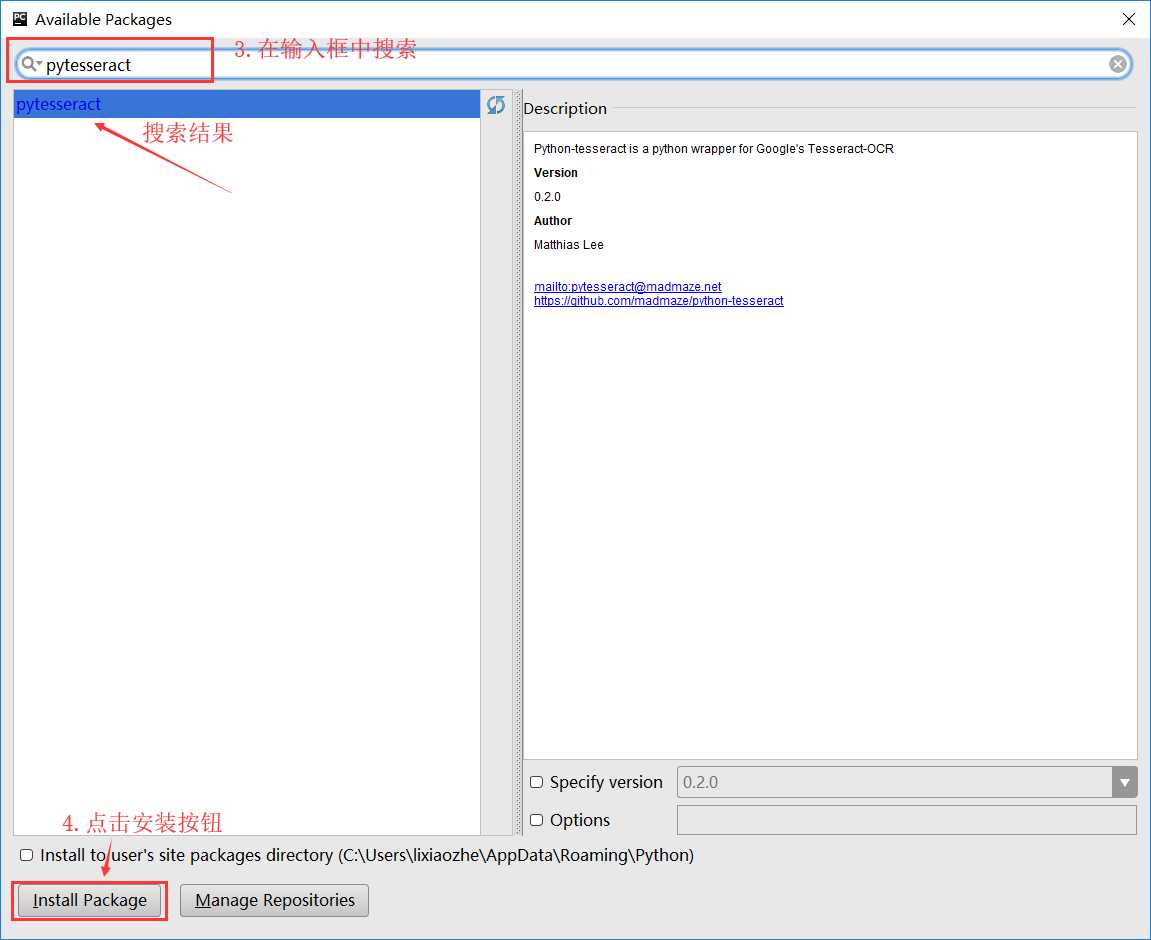
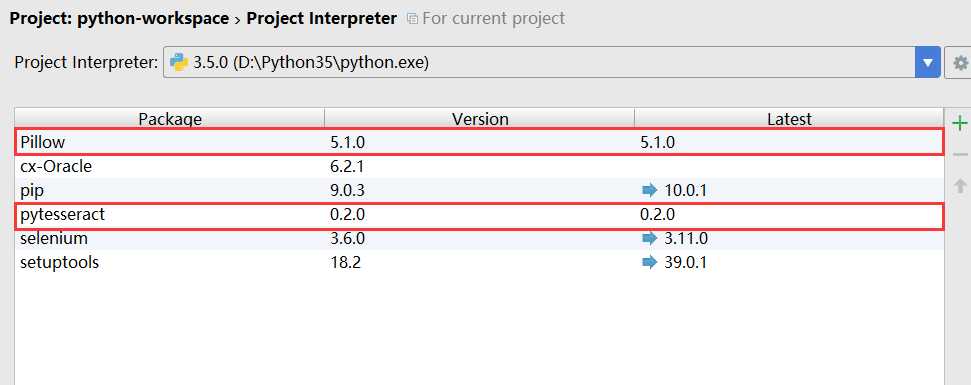
安装成功:
安装pytesseract时,同时安装pillow,所以我们只需安装pytesseract即可。
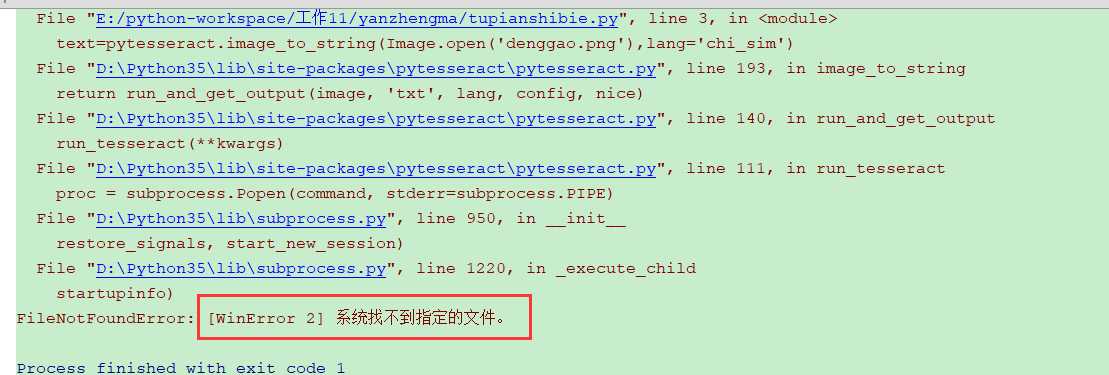
3.尝试运行,出现报错,如下图,原因:没有安装识别引擎tesseract-ocr
二、安装识别引擎tesseract-ocr
1.Tesseract是开源的OCR引擎。Tesseract最初设计用于英文识别,经过改进引擎和训练系统,它能够处理其它语言和UTF-8字符。Tesseract 3.0能够处理任何Unicode字符,但并非在所有语言上都工作得很好。Tesseract在庞大字符集语言(比如中文)上较慢,但是工作良好。
下载链接: https://pan.baidu.com/s/1J0HNoVhX8WexS_5r0k2jDw 密码: ywc3
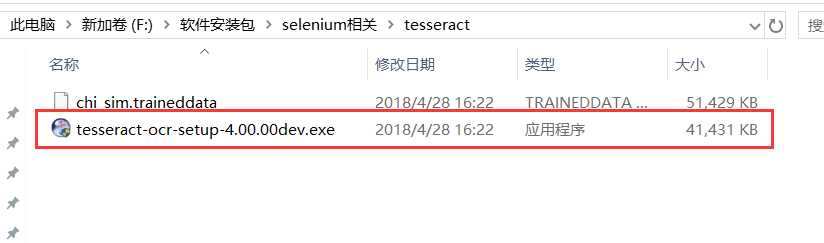
因为tesseract-ocr默认不支持中文识别。
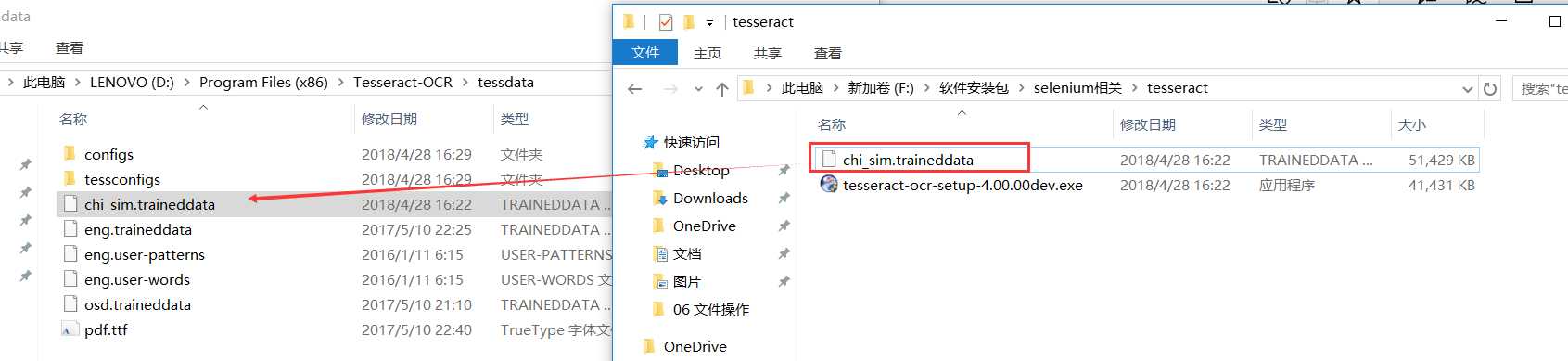
将下载到的文件:chi_sim.traineddata 放到Tesseract-OCR安装目录 D:\Program Files (x86)\Tesseract-OCR\tessdata 下,如图:
2,安装完成tesseract-ocr后,需要做一下配置 。
在Python安装目录(如:D:\Python35\Lib\site-packages\pytesseract) 中修改 pytesseract.py文件。

也可以通过pycharm,Ctrl+B 快速打开pytesseract源码文件:

3.尝试运行,出现如下报错:pytesseract.pytesseract.TesseractError: (1, ‘Error opening data file \\Program Files (x86)\\Tesseract-OCR\\chi_sim.traineddata Please make sure the TESSDATA_PREFIX environment variable is set to your "tessdata" directory. Failed loading language \‘chi_sim\‘ Tesseract couldn\‘t load any languages! Could not initialize tesseract.‘)

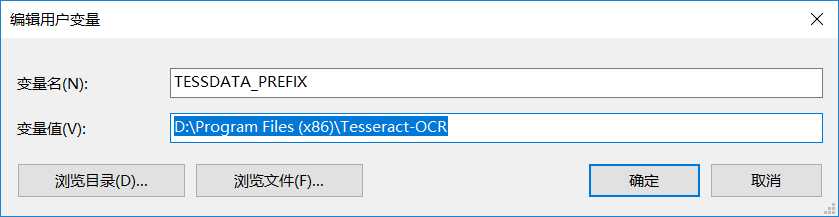
4.解决方法:将tessdata目录的上级目录所在路径:(默认为tesseract-ocr安装目录)添加至TESSDATA_PREFIX环境变量中,如下图:
注意:配置完环境变量需要重新打开pycharm编辑器(IDE)。
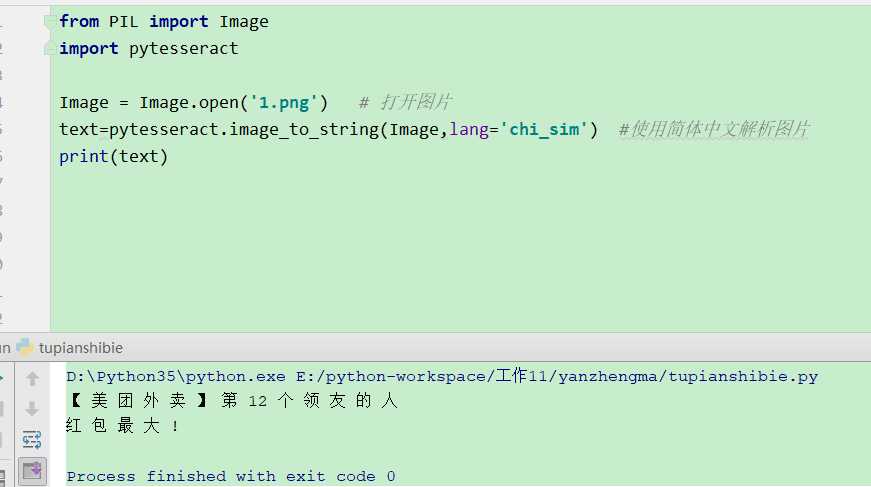
5.测试结果:图片识别成功!
但识别率不是很高,后期再调教。